چکیده
هوش مصنوعی، مهاجم یا مدافع سایبری؟ پژوهش حاضر به بررسی تقارن نامتقارن میان کاربردهای تهاجمی و تدافعی هوش مصنوعی در حوزه امنیت سایبری میپردازد. در جبهه تهاجمی، ظهور بدافزارهای مجهز به مدلهای زبانی بزرگ (LLM) با قابلیت بازنویسی لحظهای کد و تطبیقپذیری هوشمند، و همچنین حملات فیشینگ عمیق مبتنی بر تولید محتوای پویا و فوقشخصیسازیشده، ساختار دفاع سنتی را با چالشی بیسابقه مواجه ساخته است. در مقابل، نسل جدید سامانههای دفاع خودکار مبتنی بر «هوشمصنوعی عامل» با قابلیت استدلال، برنامهریزی و اقدام مستقل، نویدبخش تحول در مراکز عملیات امنیت (SOC) است. این مقاله با مرور نظاممند پژوهشهای اخیر و مستندات تجربی، شکاف موجود میان سرعت تکامل حملات هوشمند و بلوغ دفاعهای خودکار را تحلیل میکند. همچنین با استناد به چارچوبهای بینالمللی نظیر NIST AI RMF، ISO/IEC 42001، MITRE ATLAS و OWASP، الزامات حاکمیتی و استانداردهای ارزیابی این سامانهها را تبیین مینماید. در نهایت، با تأکید بر لزوم ایجاد زیرساختهای آزمایشگاهی پیشرفته شامل محیطهای شبیهساز حملات هوشمند، بانکهای داده بزرگمقیاس و چارچوبهای ارزیابی استاندارد، نقشه راهی برای توسعه دفاعهای مبتنی بر عامل در برابر تهدیدات مبتنی بر هوش مصنوعی ارائه میگردد.
واژگان کلیدی: هوش مصنوعی تهاجمی، هوش مصنوعی تدافعی، بدافزار خودتطبیقدهنده، فیشینگ عمیق، هوش مصنوعی عامل، امنیت سایبری خودکار، چارچوبهای حاکمیتی، آزمایشگاه امنیت هوش مصنوعی
مقدمه
گذار از عصر اتوماسیون به عصر هوشمندی مستقل، مرزهای امنیت سایبری را بازتعریف کرده است. هوش مصنوعی دیگر صرفاً یک ابزار کمکی نیست، بلکه به عاملی فعال در میدان نبرد سایبری تبدیل شده است. آنچه صحنه ژئوپلیتیک و اقتصاد دیجیتال امروز را شکل میدهد، «تقارن دوطرفه هوش مصنوعی» است. از یک سو، حملات مبتنی بر هوش مصنوعی که توانایی تطبیق و پنهانسازی بیسابقهای یافتهاند، و از سوی دیگر، سامانههای تدافعی مبتنی بر هوشمصنوعی عامل که استقلال عمل و قابلیت استدلال هوشمندانه را به خدمت دفاع سایبری میگیرند.
شواهد تجربی نشان میدهد که ۹۳٪ از رهبران امنیتی انتظار دارند تا پایان سال جاری با حملات روزانه مبتنی بر هوش مصنوعی مواجه شوند و ۶۵٪ معتقدند هوش مصنوعی تهاجمی به زودی به هنجار غالب در جرایم سایبری تبدیل خواهد شد [[i]]. این آمار هشداردهنده، ضرورت بازطراحی بنیادین معماریهای دفاعی را آشکار میسازد.
در این مقاله، نخست مکانیسمهای هستهای حملات پیشرفته مبتنی بر هوش مصنوعی (بدافزارهای خودتطبیقدهنده و فیشینگ عمیق) را تحلیل میکنیم. سپس، به بررسی معماری و کارکردهای هوش مصنوعی عامل در دفاع خودکار میپردازیم. در ادامه، با استناد به استانداردهای بینالمللی، چارچوب حاکمیت و ارزیابی این سامانهها را تبیین کرده و در نهایت، بر الزامات زیرساختی و آزمایشگاهی برای تحقیقات مؤثر در این حوزه تأکید میکنیم.

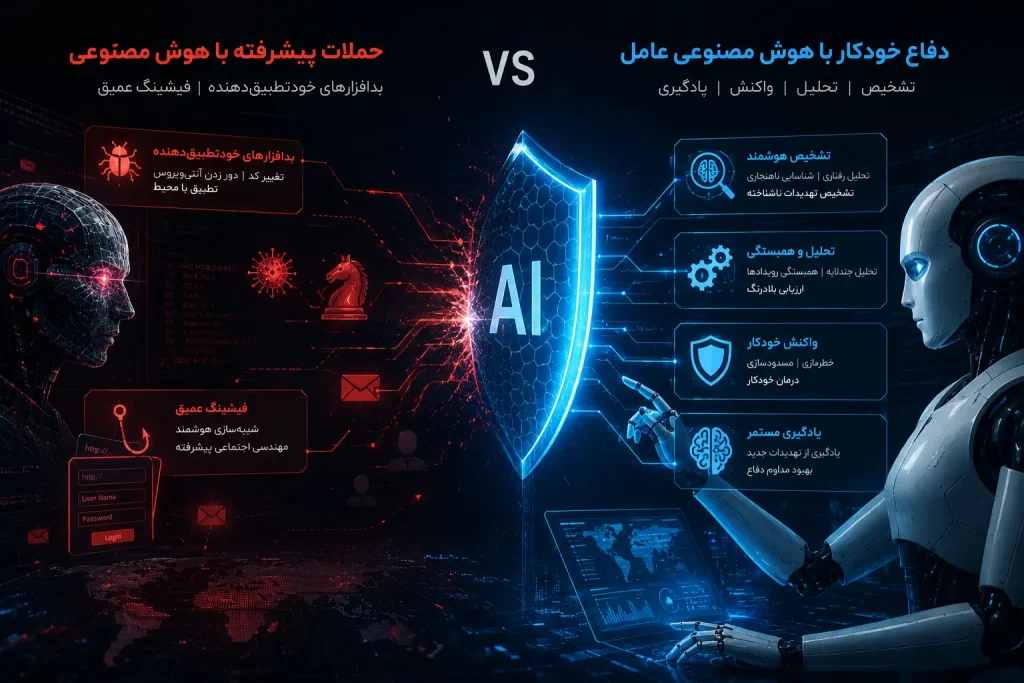
جبهه تهاجمی، هوش مصنوعی در خدمت حملات پیشرفته
بدافزارهای خودتطبیقدهنده[1]
نسل جدید بدافزارها از قابلیتهای استنتاجی مدلهای زبانی بزرگ (LLM) بهره میبرند تا در زمان اجرا، ساختار و رفتار خود را اصلاح کنند. این ویژگی که «خودتطبیقی پویا[2]» نامیده میشود، چالش اساسی برای سیستمهای تشخیص مبتنی بر امضا ایجاد کرده است.
بر اساس گزارش گروه تهدیدات گوگل[3]، نمونههای متعددی از بدافزارهای مجهز به هوش مصنوعی شناسایی شدهاند که از طریق API به مدلهای Gemini یا Hugging Face متصل شده و کد مخرب خود را در لحظه بازنویسی میکنند. از جمله این نمونهها میتوان به PromptFlux اشاره کرد که با درخواست تکنیکهای مبهمسازی و فرار از مدل، خود را در پوشه Startup تداوم میبخشد، یا PromptSteal که با فراخوانی مدل Qwen2.5-Coder، دستورات PowerShell برای سرقت فایلها از پوشههای حساس تولید میکند [[ii]]. همچنین بدافزار QuietVault به عنوان یک سرقتدهنده اعتبار، از ابزارهای خط فرمان مبتنی بر هوش مصنوعی برای جستجوی توکنهای NPM و GitHub استفاده میکند.
نکته حائز اهمیت آن است که این بدافزارها محدود به اتصال آنلاین به سرویسهای خارجی نیستند. پژوهشها نشان میدهد که مدلهای کوچکشده و بهینهشده (Quantized LLMs) میتوانند به صورت محلی در بدافزار تعبیه شوند تا امکان عملکرد در «محیطهای جدا شده»[4] را فراهم آورند [[iii]]. این معماری، بدافزار را قادر میسازد تا با تحلیل پاسخهای سیستم دفاعی، استراتژی حمله خود را بهینهسازی کند، ویژگی که آن را به یک عامل هوشمند خودمختار در سمت تهاجمی تبدیل میکند.
فیشینگ عمیق[5] و جنگ شناختی
فیشینگ سنتی با متنهای پر از غلط املایی و ساختارهای قالبی، به تدریج جای خود را به «فیشینگ عمیق» مبتنی بر محتوای تولیدشده توسط هوشمصنوعی مولد (GenAI) میدهد. این حملات نه تنها از نظر زبانی بینقص هستند، بلکه از توانایی «فوقشخصیسازی» و «بافتآگاهی» نیز بهره میبرند.
یک مطالعه نظاممند جامع (SoK) در arXiv نشان میدهد که محتوای فیشینگ تولیدشده توسط LLM، نرخ کلیک[6] حدود ۳۰٪ بالاتر از متنهای انسانی دارد و این حملات منجر به خساراتی بیش از ۴۵ میلیارد دلار تنها در سه ماهه اول سال ۲۰۲۵ شدهاند [[iv]]. این مطالعه ۹ مرحله برای دور زدن حصارهای ایمنی LLM توسط مهاجمان مستند کرده و نشان میدهد که فیشینگ عمیق در دور زدن فیلترهای ایمیل تجاری (مانند Gmail) تا نرخ موفقیت ۸۶.۴٪ دست یافته است [iv].
مکانیسم اصلی این حملات، «دستکاری شناختی» هدفمند است. با تحلیل دادههای منبعباز (OSINT) از شبکههای اجتماعی، مهاجم میتواند سناریوهایی را تولید کند که با رویدادهای واقعی زندگی قربانی (سفر، خرید، رویداد شغلی) همپوشانی داشته باشد. این سطح از بافتآگاهی، تشخیص خودکار را برای الگوریتمهای سنتی تقریباً غیرممکن میسازد [[v]]. مدلهای تشخیص مبتنی بر DeBERTa در مواجهه با حملات بازنویسی مبتنی بر LLM، تنها امتیاز F1 معادل ۰.۳۸ کسب میکنند که نشاندهنده ناتوانی جدی این رویکردهاست [iv].
جبهه تدافعی، هوش مصنوعی عامل و دفاع خودکار
از تحلیلگر تا عامل، تحول در مرکز عملیات امنیت
در نقطه مقابل حملات هوشمند، نسل جدیدی از سامانههای دفاعی مبتنی بر هوش مصنوعی عامل در حال ظهور است. برخلاف مدلهای سنتی هوش مصنوعی که صرفاً به طبقهبندی تهدیدات میپرداختند، سامانههای «عامل» دارای سه ویژگی بنیادین هستند: «جهتگیری هدفمند»[7]، خودمختاری[8] و تطبیقپذیری[9][[vi]].
یک عامل دفاعی خودکار میتواند بدون انتظار برای فرمان انسانی، زنجیرهای از اقدامات را برنامهریزی و اجرا کند. از بررسی هشدارها و همبستگی رویدادها در هزاران نقطه پایانی، تا ایزوله کردن میزبانهای آلوده، بازنویسی قوانین فایروال، و حتی هماهنگی با سایر عوامل برای پاسخ به حادثه. در کنفرانس RSA 2025، این رویکرد به عنوان یک موضوع محوری معرفی شد و نشان داده شد که «زمان شناسایی و مهار»[10] به طور قابل توجهی کاهش میدهد [vi].
چالشهای حاکمیتی و امنیت عوامل
با این حال، استقلال عمل این عوامل، سؤالات پیچیدهای درباره پاسخگویی و امنیت ایجاد میکند. یک عامل خودمختار ممکن است هدف هدایتگری معکوس (Adversarial Prompting) قرار گیرد؛ به عنوان مثال، مهاجم میتواند با تزریق «دادههای مسموم[11] یا «دستورات ویژه»[12] ، عامل تدافعی را فریب دهد تا یک سیستم حیاتی را خاموش کند یا یک تهدید واقعی را نادیده بگیرد [vi] [[vii]].
علاوه بر این، «سوگیری اتوماسیون»[13] یک چالش شناختی-انسانی جدی است. تحلیلگران انسانی ممکن است به تدریج وابستگی کامل به تصمیمات عامل پیدا کرده و توانایی نقد و بررسی خروجیهای آن را از دست بدهند [vi]. این مسئله به ویژه در سناریوهایی خطرناک است که عامل هوش مصنوعی در لبههای دانش تصمیم میگیرد.
استانداردها و چارچوبهای بینالمللی
برای حاکمیت بر این فضای دوطرفه، مجموعهای از استانداردها و چارچوبها تدوین شدهاند که هر دو سوی معادله را پوشش میدهند. این استانداردها نه تنها راهنمای پیادهسازی دفاعهای مبتنی بر عامل هستند، بلکه سناریوهای حمله به سیستمهای هوش مصنوعی را نیز مدل میکنند.
| نام چارچوب یا استاندارد | حوزه پوشش | کاربرد در هوش مصنوعی دوطرفه |
| MITRE ATLAS | تاکسونومی حملات به سیستمهای AI (مسمومیت داده، فرار مدل، سرقت مدل) [[viii]] | مدلسازی تهدیدات علیه مدلهای دفاعی و طراحی آزمایشگاه Red-Teaming |
| NIST AI RMF (2023) | مدیریت ریسک چرخه حیات AI (نگاشت، اندازهگیری، مدیریت، حاکمیت) [[viii [[ix]] | ایجاد چارچوب ارزیابی برای دفاعهای مبتنی بر Agentic AI |
| ISO/IEC 42001 (2023) | سیستم مدیریت هوش مصنوعی (AIMS) – معادل ISO 27001 برای AI [viii][ix] | صدور گواهینامه برای سامانههای دفاع خودکار و تضمین شفافیت |
| OWASP Top 10 for LLMs | ریسکهای امنیتی خاص مدلهای زبانی (مانند Prompt Injection، افشای اطلاعات) | ارزیابی آسیبپذیری دفاعهای مبتنی بر LLM در برابر حملات مهندسی اجتماعی معکوس |
| NIST AML Taxonomy | طبقهبندی حملات Adversarial Machine Learning (Evasion, Poisoning, Extraction) [viii] | طراحی تستهای نفوذ پیشرفته برای ارزیابی استحکام مدلهای تشخیص |
این استانداردها همگی بر دو اصل تأکید دارند، شفافیت[14] و «قابلیت حسابرسی»[15]. هر عاملی که در محیط دفاعی عمل میکند باید یک «جعبه سیاه» نباشد. الگوریتمهای تفسیرپذیری (Explainable AI – XAI) باید قادر به بازگرداندن زنجیره استدلال عامل به زبان انسانی باشند تا در صورت تصمیم اشتباه، بتوان ریشه خطا را شناسایی کرد [vi].
ضرورت زیرساختهای آزمایشگاهی پیشرفته
یکی از موانع اصلی در پیشبرد مرزهای دانش در حوزه هوش مصنوعی دوطرفه، نبود زیرساختهای آزمایشگاهی استاندارد و قابل تکرار است. پژوهش مؤثر در این حوزه نیازمند محیطهایی است که همزمان توانایی شبیهسازی حملات پیشرفته و ارزیابی دفاعهای خودکار را داشته باشند.
مؤلفههای آزمایشگاه مؤثر
بر اساس تحلیل شاخصهای بینالمللی ارزیابی مدلهای امنیت سایبری، یک آزمایشگاه مرجع باید دارای ویژگیهای زیر باشد [[x]].
پوشش حوزه تخصصی[16]
آزمایشگاه باید قادر به شبیهسازی طیف کامل زیرحوزههای امنیت سایبری (تهدیدات، تحلیل بدافزار، ترافیک شبکه، پاسخ به حادثه و …) باشد.
لایهبندی قابلیتها[17]
- لایه پایه: ارزیابی دانش پایه مدلها از مفاهیم امنیتی.
- لایه کاربردی: ارزیابی توانایی حل مسئله و تحلیل در سناریوهای واقعی.
- لایه پیشرفته: سنجش خلاقیت (تشخیص الگوهای نوین حمله) و مقاومت در برابر حملات مخرب[18]
دادگان مرجع[19]
دسترسی به مجموعه دادههای بزرگمقیاس از بدافزارهای واقعی، ترافیک حمله و محتوای فیشینگ. این دادگان باید بهروزرسانی شوند تا نمونههای جدید بدافزارهای خودتطبیقدهنده را شامل شوند.
چالش شاخصگذاری[20] در تقارن دوطرفه
یکی از مسائل حلنشده، طراحی شاخصهایی است که بتواند «رقابت تسلیحاتی» بین هوش مصنوعی تهاجمی و تدافعی را کمّی کند. معیارهای سنتی مانند دقت (Accuracy) یا نرخ مثبت کاذب (FPR) برای ارزیابی دفاع در برابر یک مهاجم هوشمند که در حال تکامل است، ناکافیاند. پژوهشگران پیشنهاد کردهاند که از معیارهایی نظیر «زمان مصونیت»[21] و «نرخ فرار پویا»[22] استفاده شود؛ معیارهایی که توانایی عامل دفاعی در حفظ امنیت در مواجهه با نسخههای در حال تکامل بدافزار را اندازه میگیرند [iv].
ساخت چنین آزمایشگاههایی مستلزم سرمایهگذاری قابل توجه و همکاری میانرشتهای است؛ زیرا باید قابلیت اجرای همزمان هزاران عامل خودمختار (هم تهاجمی و هم تدافعی) در یک محیط Sandbox ایزوله و ثبت تمام تعاملات آنها برای تحلیلهای پسازرخداد وجود داشته باشد.
بحث و چشمانداز آینده
آنچه از تحلیل وضعیت موجود برمیآید، یک «شکاف نامتقارن» است. در سمت تهاجمی، موانع ورود[23] در حال سقوط آزاد هستند. هر هکر تازهکاری با دسترسی به مدلهای رایگان میتواند بدافزارهای پویا یا کمپینهای فیشینگ فوقشخصیسازیشده ایجاد کند [i][iii]. مدلهای زبانی به مهاجم این امکان را میدهند که کد مخرب با معماریهای مختلف تولید کند.
اما در سمت تدافعی، پیادهسازی هوش مصنوعی عامل بسیار پرهزینه و پیچیده است. نیاز به حاکمیت دقیق برای اقدامات پرخطر، تضمین عدم وجود سوگیری، و هزینه بالای محاسباتی برای استدلال در لحظه، موانعی جدی پیش روی سازمانها قرار میدهد.
یک سناریوی محتمل در کوتاهمدت، ظهور «اکوسیستمهای عامل»[24] است. در این سناریو، یک عامل تدافعی مرکزی، شبکهای از عوامل کوچکتر را در لبههای شبکه (Edge) مستقر میکند. این معماری توزیعشده، انعطافپذیری بالایی دارد، اما سطح حمله را نیز به شدت افزایش میدهد، چرا که هر عامل میتواند هدف یک حمله «تقلید هویت» یا «اخاذی منطقی» قرار گیرد [vii].
برای غلبه بر این چالشها، پژوهشهای آتی باید بر روی «معماری اعتماد شناختی»[25] متمرکز شوند. این معماری، بر خلاف مدلهای صفر-اعتماد[26] ایستا، میتواند سطح اعتماد به یک عامل را بر اساس «تحلیل لحظهای نیات»[27] و «رفتار متنی»[28] تنظیم کند و حتی در صورت شناسایی رفتار فریبکارانه، عامل را منزوی نماید [vii].
نتیجهگیری
این مقاله نشان داد که میدان نبرد امنیت سایبری وارد فاز جدیدی شده است که در آن هوش مصنوعی نه به عنوان سلاح یا سپر، بلکه به عنوان سرباز و فرمانده خودمختار ظاهر میشود. بدافزارهای خودتطبیقدهنده و فیشینگ عمیق، مرزهای تشخیصپذیری را جابهجا کردهاند و دفاع سنتی را منسوخ ساختهاند. در مقابل، هوش مصنوعی عامل با ارائه قابلیت استدلال و اقدام مستقل، امیدی تازه برای غلبه بر سرعت و پیچیدگی حملات فراهم آورده است.
با این حال، استقرار مؤثر این فناوری مستلزم رعایت سه پیشنیاز حیاتی است. اول، پیادهسازی چارچوبهای حاکمیتی ترجیهاً بومی و یا حداقل بینالمللی (همچون NIST، ISO/IEC 42001) برای تضمین شفافیت و پاسخگویی عوامل هوشمند. دوم، سرمایهگذاری هدفمند در زیرساختهای آزمایشگاهی پیشرفته که قادر به شبیهسازی «جنگ نامتقارن» بین هزاران عامل تهاجمی و تدافعی باشند. سوم، بازطراحی فرآیندهای نیروی انسانی برای حرکت از نقش «اپراتور» به «ناظر-راهنما»[29] که زنجیره تصمیمگیری عامل هوشمند را درک و تأیید کند.
در نهایت، تنها رویکردی در این رقابت هوشمندانه پیروز خواهد شد که بتواند تعادل میان «سرعت و خودمختاری» از یک سو و «ایمنی و حاکمیت» از سوی دیگر را برقرار سازد.
پانویسها
[1] Self-Adaptive Malware
[2] Dynamic Self-Adaptation
[3] GTIG
[4] Air-gapped
[5] Deep Phishing
[6] Click-Through Rate
[7] Goal Orientation
[8] Autonomy
[9] Adaptivity
[10] Detection & Containment Latency
[11] Poisoned Data
[12] Prompt Injection
[13] Automation Bias
[14] Transparency
[15] Auditability
[16] Domain Coverage
[17] Capability Layering
[18] Adversarial Robustness
[19] Benchmark Datasets
[20] Benchmarking
[21] TTC: Time to Compromise
[22] Dynamic Evasion Rate
[23] Barriers to Entry
[24] Agentic Ecosystems
[25] Cognitive Trust Architecture
[26] Zero Trust
[27] Intent Analysis
[28] Contextual Behavior
[29] Supervisor-Mentor
منابع
[i] Netacea, “Cyber security in the age of offensive AI,” Global Security Mag, 2026.
[ii] Google Threat Intelligence Group (GTIG), “Emerging Techniques in LLM-Powered Malware,” via ThaiCERT, Nov. 2025.
[iii] F. Chen et al., “SoK: Exposing the Generation and Detection Gaps in LLM-Generated Phishing,” arXiv preprint arXiv:2508.21457, 2026.
[iv] L. Chourey, “From Analyst to Agent: Governing Autonomous AI in the Modern SOC,” RSA Conference, 2025.
[v] “生成式AI赋能的网络钓鱼攻击机制与语义防御架构研究,” (Generative AI-powered Phishing Attack Mechanisms and Semantic Defense Architecture), Alibaba Developer, 2026.
[vi] K. I. Iyer, “Cognitive Trust Architecture for Mitigating Agentic AI Threats: Adaptive Reasoning and Resilient Cyber Defense,” Journal of Information Systems Engineering and Management, vol. 10, no. 47s, 2025.
[vii] Red Hat, “Harden your AI systems: Applying industry standards in the real world,” Dec. 2025.
[viii] National Institute of Standards and Technology (NIST), “Artificial Intelligence Risk Management Framework (AI RMF 1.0),” 2023.
[ix] International Organization for Standardization (ISO), “ISO/IEC 42001:2023 – Artificial intelligence — Management system,” 2023.
[x] “网络安全大模型测试指标体系设计思路” (Design Ideas for Cybersecurity Large Model Testing Indicator System), Sec-RSS, Aug. 2025.
درباره نویسنده
احتمالاً این مطالب را هم میپسندید
-
دوقلوی دیجیتال و کاربرد آن در سامانههای نظارت تصویری
-
هوش مکانی در سامانههای نظارت تصویری
-
تحلیل تخصصی استانداردهای IEC 62676 و چرایی عدم کارایی در امنیت سایبری سامانههای نظارت تصویری
-
کاربرد بلاکچین و رمزنگاری کوانتومی در ویدیو و سامانههای نظارت تصویری
-
نقش سامانه سپتام در ارتقای اعتماد عمومی و مشروعیت نظارت تصویری در اماکن عمومی و خصوصی